
In the field of artificial intelligence (AI) and machine learning, temperature is a key parameter that plays an important role in influencing the output of large language models (LLMs). Specifically, temperature helps control the level of randomness in the text generated by these models during inference, which is the process where the model produces text in response to a prompt.
To understand temperature, it’s helpful to look at how LLMs generate text. These models work by predicting the next word — or more accurately, the next token — based on a probability distribution. Each potential token is assigned a numerical value called a logit. These logits are then passed through a mathematical function known as the softmax function, which converts them into probabilities:
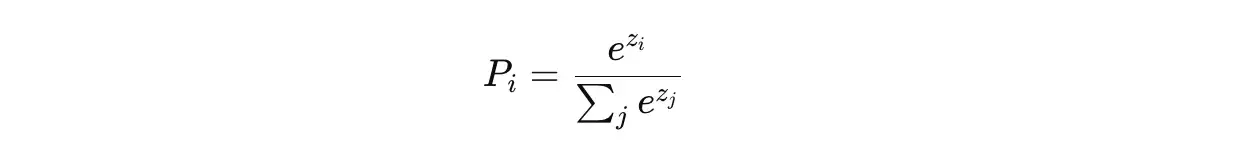
The result is a softmax probability distribution in which all the token probabilities add up to one. The temperature parameter modifies this distribution before the next token is selected.
When the temperature is set to a low value, the model becomes more conservative in its token choices, favoring the most probable options. This leads to more consistent, focused, and predictable output. In contrast, a high temperature increases the likelihood of the model choosing less probable tokens, thereby introducing more variability and randomness into the response. This can result in outputs that are more surprising, diverse, or even creatively unexpected. Essentially, temperature controls how “adventurous” or “safe” the model’s responses are.
This adjustability makes temperature a crucial setting for tailoring LLM behavior across a wide range of applications. If your task requires precise, fact-based responses — like writing technical documentation, producing business reports, or answering customer support queries — a lower temperature is usually best. It ensures the model sticks closely to the most likely and relevant words or phrases, avoiding tangents and errors. On the other hand, if you’re brainstorming ideas, writing poetry, or working on a creative story, a higher temperature can lead to more imaginative and varied outputs.
It’s common to hear people describe temperature as a “creativity setting”, but this is only partially accurate. A better way to think about it is in terms of how widely the model draws from its training data when making choices. In a study by Max Peeperkorn and colleagues, researchers analyzed how different temperature values affected model outputs. They found that while higher temperatures are loosely associated with novelty and slightly more unexpected results, they can also lead to less coherent output. Interestingly, the study showed no strong correlation between temperature and typicality or cohesion. In other words, while temperature affects novelty, it doesn’t directly control creativity in a reliable way.
In practice, most LLM APIs — including platforms like IBM® Granite™ Instruct or OpenAI’s ChatGPT — offer temperature as one of several parameters that users can configure. Other related parameters include:
do_sample: This setting determines whether the model uses sampling to generate its output. If set to True, the model will sample from the probability distribution (influenced by temperature) instead of always choosing the most probable token. This must be enabled for temperature to have any effect.
top_k: This parameter limits the sampling pool to the top k most probable tokens. It keeps generation within a more focused set of choices, helping maintain output quality while still introducing variation.
top_p (also known as nucleus sampling): Instead of fixing a number of top choices, this method includes the smallest number of tokens whose combined probability exceeds a certain threshold (e.g., 95%). It helps the model stay coherent while still allowing some creative freedom. The general recommendation is to alter temperature or Top P but not both.
In addition to these, there are further parameters designed to manage and shape the LLM’s output:
Maximum length: This limits how many tokens the model is allowed to generate in response to a prompt. It’s useful for preventing excessively long outputs.
Stop sequences: These are predefined tokens or phrases that tell the model when to stop generating. For example, including “Sincerely,” or “Best regards,” as a stop sequence can signal the end of an email.
Frequency penalty: This discourages the model from repeating the same tokens too frequently by penalizing words that have already appeared often in the output.
Presence penalty: Unlike the frequency penalty, this setting penalizes the reuse of tokens based on whether they have appeared at all, encouraging the model to explore new vocabulary.
In summary, temperature is a foundational control that helps users balance creativity, randomness, and coherence in LLM outputs. When used thoughtfully alongside related parameters, it offers powerful flexibility for tailoring AI-generated text to specific tasks and contexts.
To see how temperature affects the output of an LLM, look at the outputs created by the IBM Granite 3.1 2 billion parameter model. The prompt provided here was: “Write a story about a data scientist who loves Python.”
With a temperature of 0.1 Granite generates:
Once upon a time, in the bustling city of San Francisco, there lived a brilliant data scientist named Alex. Alex was known for their exceptional skills in Python programming and data analysis. They spent their days and nights immersed in the world of data, using Python to extract insights and make predictions.
One day, Alex was tasked with analyzing customer churn for a popular streaming service. They used Python's scikit-learn library to build a machine learning model that could predict which customers were likely to cancel their subscriptions.
With a temperature of 0.75 Granite generates:
Once upon a time, in the bustling city of San Francisco, there lived a brilliant data scientist named Alex. Alex was known for their deep love for Python, a programming language that they believed was the perfect tool for data analysis and machine learning.
Every day, Alex would wake up early, brew a pot of coffee, and sit down at their desk. They would spend hours writing code in Python, exploring datasets, and building predictive models. Their love for Python was not just about the language itself, but also about the community that had grown around it.
With a temperature of 1.25 Granite generates:
Once upon a time, in a bustling city filled with towering skyscrapers and neon lights, there was a data scientist who loved Python more than anything in the world. The data scientist has a feline helper named Suki. Suki is a curious and playful cat, always eager to explore every nook and cranny of the house.
One day, the data scientist is working on a complex coding problem. Suki keeps meowing loudly as if she is trying to communicate a message to the data scientist. The data scientist notices that the loud meowing usually happens when they are close to a solution to the complex coding problem.
Even though each story starts with a similar beginning, increasing the temperature increases the variability of the text and the details that are generated.